Two Ways To Evaluate Which Event-Driven Architecture is Right for Your Flow Systems
The event-driven platforms market is a confusing place. In fact, there is an entire appendix in Flow Architectures: The Future of Streaming and Event-Driven Integration dedicated to evaluating much of that market and it's almost a third of the book. Thus, it is no surprise that developers and architects not experienced with eventing systems struggle to identify the best platform for their applications.
I've identified one method for making a selection in the book, which I will update in this blog post to reflect what I have learned since the book came out. I used a model based on the types of event streams, which works extremely well if you are going to consume a stream over which you have little control. (It also works for selecting technologies within a scope you control, but I am more interested in how you "future-proof" your decisions for a flow future.)
Another interesting way to slice the market comes from researcher Jamie Brandon, who looked at the problem from the perspective of the data processing required to process the streams, using factors such as whether or not the data is structured and the need for internal consistency.
I'll give a brief overview of both methods, and talk a little about when you might use one over the other—or both as complementary approaches to different aspects of an often complex question.
Evaluating Stream Consumption
One of the "aha" moments of writing the book occurred while organizing the last chapter, which explores things companies can do today to prepare for a flow future. Clemens Vasters, who is the lead architect for messaging and eventing services for Microsoft Azure, introduced me to a talk he gave about selecting the right architectures for your use cases. (I embedded the YouTube video at the bottom of this post for convenience.) From that talk, and subsequent conversations, I put together a decision tree that helps make those decisions based on the stream type. The diagram below is an update to the one in the book, as I was always uncomfortable with the fact that Swim.ai and AWS Lambda ended up in the same box in the original effort.
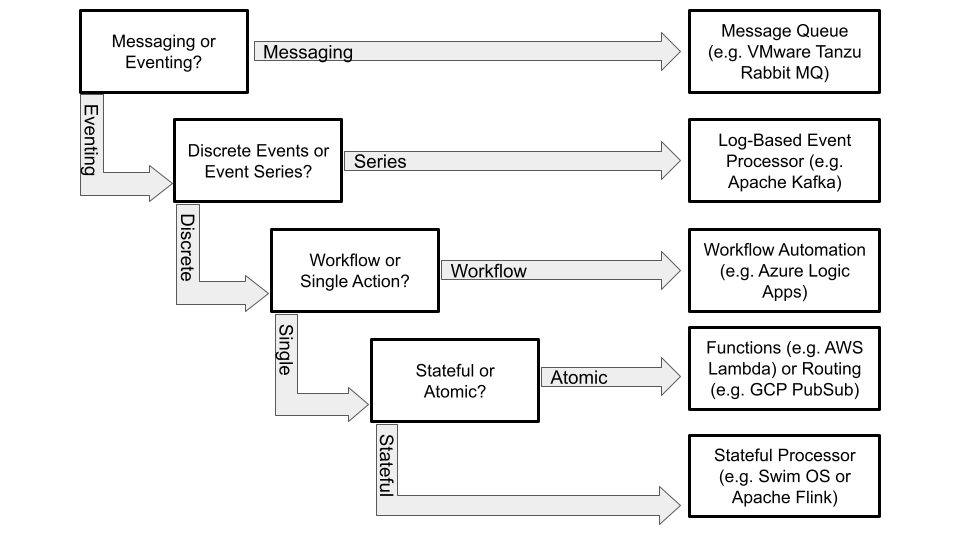
What I love about this approach is that it is usually (but not always) apparent early in the evaluation of a given eventing use case what the data represents and how it needs to be consumed. If you are building a system to model real world systems, you are probably most interested in maintaining a stateful processing model, as rebuilding state for every evaluation is expensive. On the other hand, if you are evaluating in real time the patterns present in event streams, you might do better with a log-based queue, like Apache Kafka.
These aren't hard and fast rules, of course. Many of these systems can be applied to other use cases if required with reasonable performance. However, choosing the right tool for the job simplifies both programming and operation of flow-ready systems.
Here's a quick summary of the different terms in the tree above:
Messaging vs Eventing: Is your system going to maintain a conversation between two agents in which both agents will exchange events with the other? That type of communication fits a messaging model very well, as the queues can be used as buffers for asynchronous communication, and the topic model allows a number of ways to separate message traffic, guarantee delivery, and so on. On the other hand, if you are closer to the flow model of a producer creating events for one or more consumers to process, and there is no expectation for the consumer to reply, an eventing model is the right choice, as messaging systems are challenged with both scale and performance relative to other options for event processing.
Discrete Events or Event Series: The primary question to be answered here is whether or not your use case will require you to retrieve or replay a series of related events in order to complete its processing. There are a wide variety of uses for event series, as indicated by the success of Apache Kafka in the market today. Being able to set a cursor in a topic to some point in time and read events from that point forward can be very useful for rebuilding database or in memory agent state, running pattern recognition algorithms to identify a sequence of events that would require action, or simply using an actual event stream as input to a model for development or testing. Discrete events, however, also have their use, especially where immediate reaction to any given state change is required.
Stateful or Atomic? Atomic actions are ones in which the event state can be forgotten by the processing system once the action is taken. So-called Functions-as-a-Service offerings (e.g. AWS Lambda) generally work this way—the idea is to write functions that are stateless and idempotent. A function might write to a data store of some kind, but no event state will remain in the function's process once that action has taken place. Stateful processing, on the other hand, will track and store state for stream data both during and after processing, which allows the developer to build a model of the producer environment represented by the event stream. This is actually an extremely powerful approach for such uses as simulation or operational awareness.
Workflow or Single Action? When an event requires action, will you need to do a single, immediate step, or does that state change trigger a coordinated process of steps that in term may trigger events or API calls to a number of services? The latter is extremely common in situations where an orchestrated response is required to that event. The former is more common when the event stream is being used to take a single action, such as firing a function or updating a table.
Generally, the event processing platforms I have researched fall into at least one of these architecture categories, but as I noted earlier, many can be used for multiple purposes. For example, Kafka is perfectly capable of streaming discrete events, though it generally does not provide any advantage to do so over an event routing service like GCP PubSub or Azure EventHub.
Event stream use is not the only way to make a decision, however. Let's explore Brandon's "opinionated map" as an alternative.
Evaluating Data Processing Properties
What Brandon presents in her blog post is what she calls an opinionated map of technologies as applied to three data factors. The map is less of a selection criteria tree, like mine, but rather segregates technology options by various criteria, some of which are less desirable than others. Her decision criteria is quite different from mine, given the focus on data properties rather than stream use cases.
(This is a screen capture, so the links don't work. If you want to click a link, please open Brandon's post where you will find the functioning diagram.)

Here, you are guided to selecting technical options based on the nature of the data you receive and the processing properties supported by the stream processing system. What is interesting about this model is that it pays close attention to how event data is handled within each processing option. In distributed systems, like most flow applications, this is important, as not acknowledging various tradeoffs can lead to inconsistent and incorrect processing.
Here is a summary of Brandon's terms. Not being a data scientist, I can only attempt to do the definitions justice. Detailed (and accurate) descriptions are available in her post.
Unstructured vs Structured Systems: Unstructured systems allow arbitrary collections of calculations and other actions to be applied to incoming data, acting as a composable collection of data and code. Because it is arbitrary, the software must do additional work to identify which computations are required for a given event. While those computation graphs can be maintained for future calculations when the inputs change, there is still significant overhead required to identify, assemble, then execute each arbitrary graph. Structured systems, on the other hand, have fixed computational graphs which optimize processing for a specific way of doing things for each event (or, often, group of events).
High Temporal Locality vs Low Temporal Locality: This is just a very academic way of saying "stateless" versus "stateful", as I read it. If your calculations can be executed without knowing prior state, then it has high temporal locality. If it requires knowing prior state (e.g. a bank balance before adding a new deposit), then it has low temporal locality. It is interesting to see how several "streams" branded products are targeted at stateless processing, though the addition of database-like behavior moves it into the low temporal locality camp. A slightly different way of looking at those product lines than I had considered. Regardless, there is some interesting overlap, as well.
Internally Consistent vs Internally Inconsistent: One factor Brandon considers that I do not in my tree is whether or not your stateful processing can abide inconsistency in the distributed representation of state. Internally consistent systems will guarantee that any set of inputs will produce a correct output, avoiding race conditions like eventual consistency. Internally inconsistent systems will allow incorrect processing in some conditions. Brandon has a clear preference for internally consistent systems (as I am sure most of you do too), but notes that eliminating internally inconsistent systems removes much of the stateful processing options she has on her list. Oh, and there is this little insight that explains why so many are considered internally inconsistent:"Many popular systems allow internal inconsistency under various scenarios. This information is usually buried in the documentation rather than being clearly advertised. As a result people using these systems often believe that they will produce consistent results. To compound this confusion, it's common that such systems will behave well during development and only later in production start to quietly produce incorrect results under pressure."
Obviously, this model is more directed at streamed data processing (e.g. replacing a batch processing system with a live data stream), rather than, say, stateful modeling of systems. However, I think the questions raised here are worth thinking about regardless of your use of events and streams.


Comments
Post a Comment